Document API First
A few years back – there was an upsurge in ‘Design Methodology’, wherein proponents of this method propagated an API first design, recommended writing REST API for all business logic – which could be consumed by anyone within or outside of an organization. The idea was that even when being used by a webapp, the business logic should be exposed as REST API, and any future integrations with mobile or other third party tools will consume the same REST API’s. However, API’s cannot be consumed sans documentations – thus came into existence the “Document API First Model”.
The ‘Document API First Model’ demands that all document be completed ready for consumption by a human or a machine before a single line of code is written – this means the document is structured and not a free-flowing one. In our experience, the documents help lessen the ambiguity, as we have the option to get further validation from the clients.
While there are many ways to document the REST API’s we have found “SWAGGER” to be useful (Swagger has been renamed ‘OpenAPI’, though still referred to as Swagger in the open source world!). A Swagger file can be used to define:
- API endpoints
- Data input format
- Output data model
- Server environments
- Authentication schemes etc.
- Detailed specifications can be found here.
Now, the choice comes down to whether, to write this documentation or generate this documentation from code. But, if code has not been set up it is advisable to write a swagger file. If a code framework is in place, we can declare API functions (note – just declare – not code), and put function headers on it as per the API documentation format. The function header can be consumed by tools to generate documentation, e.g. swagger-jsdoc
A ‘Swagger’ file is a structured file and can be viewed by anyone by just opening it in any text editor, and there are quite a few tools available to help in viewing swagger files without having to know the file structure — e.g. swagger-editor.
Use API gateway
An ‘API gateway’ is a layer between the business logic and the API documentation, and its use is imperative; the gateway ensures:
- Only valid data is passed to the API as per the API documentation.
- It also reduces the vulnerabilities in the application since data gets validated before reaching the code.
- Only the filtered data as per API documentation goes out from the server. This ensures that any kind of secret data isn’t distributed.
- Documentation never goes out of sync. Since an API gateway will ensure that only the documented APIs will be exposed to the outer world, there will be no backdoor entry into the backend.
- That clients of an API can consume APIs while a backend developer is still developing business logic for the API.
- We can mock the response of an API without even a single line of code written by a backend developer.
- This requires an integration phase when both backend developer and client are done with the code. There will be bugs to be fixed in this phase so better is the documentation, less would be the bugs in the integration phase.
- We can mock the response of an API without even a single line of code written by a backend developer.
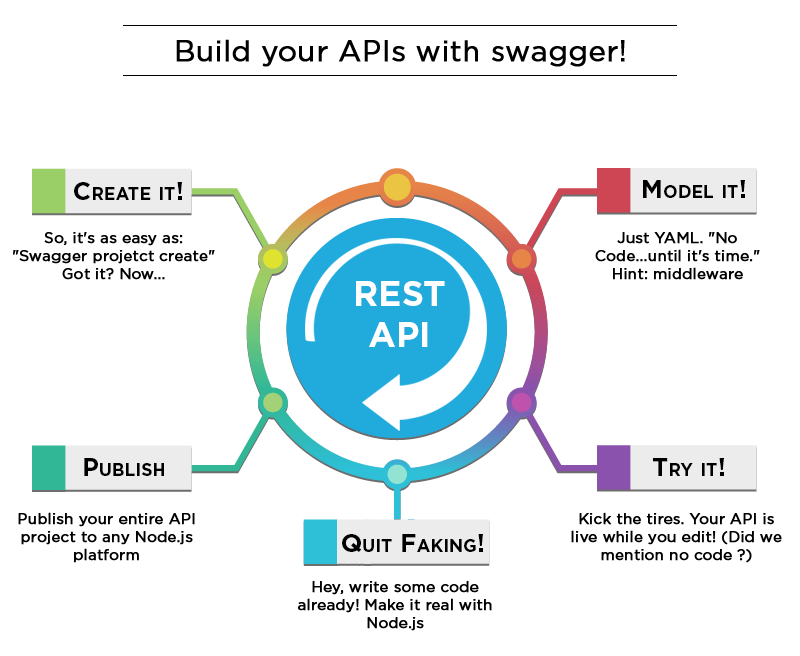
We have used ‘AWS API gateway’ in the past and there are quite a few others available, for instance there is ‘Swagger npm’ – it is quite interesting, and can be used for the projects which have nodejs as backend – we did do a POC and liked it a lot! Below is an image defining flow in this npm: Use REST specs to our advantage
REST has specs as defined by W3C and we can use it to our advantage to build REST APIs. Few of the specifications or conventions which can help us in managing client expectations as well as behavior:
- An API route should use nouns instead of verbs for identifying the resource category. Below are a few examples of good API routes as per REST conventions:
- GET /article – to get all articles
- POST /article – to create an article
- GET /article/:articleID – to get specific article
- PATCH /article/:articleID – to update specified article
- DELETE /article/:articleID – to delete specified article
- Return HTTP code as per the specifications. This wiki page which lists all the specifications concisely. Before returning any HTTP code, it is best to check the status code list if there is a better HTTP code.
- For any ‘GET all’ request, it is best to implement pagination logic. Pagination parameters like ‘page’ can be expected in route as a query parameter. Which will be used to return data for the specific page, and will not degrade the performance of client or server side by not sending a huge amount of data.
- As the name suggests for any GET request, it is important to not update the DB state. If there is a situation where DB state needs to be updated for a GET request, it needs to be in a controlled fashion and only in special situations.
Modularize auth, ACL & data validation policies
There are a couple of ways which authentication and authorization can be handled in an API.
- The least effective and most bug-filled being where auth code is written separately for each API. This approach rarely works and often introduces vulnerabilities into the application.
- Another way is to write auth code is in ‘Aspect’ also called middleware in nodeJS applications.
- And for the most effective optimization being to have a fixed set of authentication and authorization policies. Which is better than having code directly written in the aspect/middleware any day. Which complicates the auth code and is the last thing any architect or developer wants to do!
- Writing auth code directly in aspect/middleware of complex code will only complicate it further, and add even more vulnerabilities. Instead, we recommend an auth policy factory which generates auth policy based on the request passed. This auth policy needs to be triggered in aspect/middleware and asked to validate whether the API user is allowed to perform the request.
The same logic can be applied for an ACL, instead of hardcoding the logic inside each API where it can become a cross-cutting concern – like the auth policies mentioned above. Use a policy database access/update ‘where’ conditions are defined based on some common logic. Then it is just a matter of picking the right policy based on the situation.
Similarly for validation policies, the input data validation policies should be applied to avoid XSS and SQL injection attacks. Most of the frameworks take care of this by default, but it is important to check before using any framework. For avoiding SQL injection attacks, it is important to use ‘ORM’ or ‘parameterized queries’.
Log API access
Logging each API access is important for the proper analysis of quite a few factors.
Examples are:
- Country/City from which APIs are being accessed, this analysis can help in validating if an application is being built or deployed for the audience of that country.
- The frequency of the access based on time, country, IP, etc. This can be used for capacity planning of infrastructure.
- Percentage of success/failures. This can be used to identify if the application is experiencing a bug which is leading to a high percentage of failures.
We use analytic tools like the ELK (Elasticsearch Logstash Kibana) stack for this kind of analysis. Though there are quite a few other open source tools with similar analytic capabilities.
While using NodeJS, we put a server (like Apache) in front, helping to fetch access and error logs while moving to Elasticsearch using Logstash. A relatively cheaper alternative if you don’t require extensive analysis is AWS CloudWatch. Similar thing should also be done for database logs to capture slow queries.
Monitor APIs and infrastructure
We can certainly analyze logs in retrospect. Nowadays almost-real-time log analysis is also available. But if the API server is having memory leaks or draining CPU a developer will need to monitor the API server. There are also quite a few tools available in the market for this kind of monitoring. We have extensively used keymetrics — from the creator of PM2 (a module used extensively in NodeJS).
Infrastructure monitoring is very much dependent on the infra provider being used. For AWS, we monitor using AWS CloudWatch for surveillance as well as raising alarms in case of thresholds being breached.
Implement throttling on the API
This helps in preventing someone using more infrastructure than defined in pricing plans or a fair usage policy. While using an AWS API gateway you can sometimes get this feature for free. An AWS API gateway also prevents Denial of Service attacks. In general, each programming language or framework has libraries or packages available to achieve proper throttling at application server level.
About the author: With over 18 years of experience, Manpreet is the Chief Technology Officer at SourceFuse, leading the technology frat pack. Manpreet loves mentoring and running POC’s! He passed out from Thapar University (Patiala) and BITS (Pilani).
Reach out to us for any questions at support@sourcefuse.com!

