

This case study discusses how SourceFuse implemented One Call’s Driver Network using microservices architecture. Pros and Cons of adopting microservices architecture will also be explored. This paper also details on how nonfunctional requirements like reliability, efficiency, logging, etc are being handled in this implementation of a microservices architecture.
Background
The Relay Health app started off as a Minimal Viable Product Championed by a Snr. VP at One Call – a leader in providing specialized cost containment services to the Workers’ Compensation industry. Relay Health leverages leading ride-sharing service APIs in the US to book, orchestrate, manage and transport services for workers compensation cases.
The MVP was quickly validated, adopted and has scaled over the last 15 months, having served over 65k rides for injured workers. During this time SourceFuse added many features (user stories) over 25 odd sprints to the application which of course meant adding many lines of code and leaving us with a fairly large Monolith.
Problem Definition
For business reasons One Call wanted to expand the transport network beyond popular ride-sharing services and include it’s own “driver network”. This was our next big feature or “Epic”
We could have just built this feature (expose APIs and build business logic) on top of our existing application but we would have ended up with the following challenges:
- Building on top of an existing monstrous monolith increases complexity, slows down development, introduces bugs and makes testing difficult.
- An obstacle to Continuous Integration – We work in a truly agile environment, catering to new business scenarios, features and production fixes. This means we need to push changes to production often (many times a week) This is nearly impossible with a large monolith as the impact of changes is not understood fully, and to mitigate this risk we need to do extensive manual testing which is next to impossible at the required frequency of change.
- Scaling / Infrastructure optimization – All components of a monolithic application run on the same infrastructure. This results in a non-optimized utilization of resources (compute and memory) as you need to compromise on the hardware needed by each one of your components.
- Reliability – A monolith application’s bottleneck is it’s slowest component. This means that a problematic or non-performant component could bring your whole app (or all related apps) down. For instance, we did have an issue where a memory leak in a 3rd party SDK we were using to poll the ride-sharing APIs brought our entire monolith down. If our new “Driver network” was also a part of this monolith, it would have come down with it as well. With a microservices approach, these separate “business units” can be kept isolated from each other ensuring uptime.
- Flexibility – A monolithic architecture also limited us to technologies, frameworks, and databases we could use to build new features. Our monolith was built on NodeJS but if we wanted to use Python for finding the nearest driver to a patient, we couldn’t. Moving to a microservices architecture gave us this flexibility.
High-Level Solution
SourceFuse adopted microservices application architecture for One Call’s Driver Network. Microservices Architecture pattern enables each microservice to be deployed independently. While the total amount of functionality is unchanged, the application is broken into manageable chunks or services, which also enables each service to scale independently. This pattern also enables better fault isolation. Fault in one service will not degrade the efficiency or working of other services. Also, each microservice can have its own technology stack (‘polyglot stack’). Furthermore, each microservice can be enhanced without impacting its dependent services/clients using version management strategies.
Solution Details
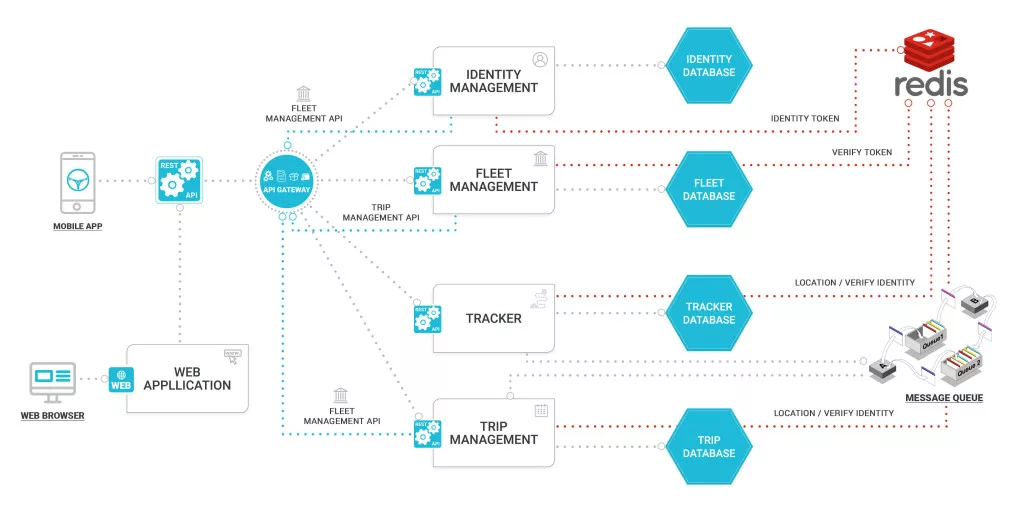
As the diagram suggests, there are multiple services together exposing application’s API using AP gateway. Each service has its own storage engine. And each service also exposes REST API to be consumed by API gateway users as well as other services. Services notify each other about data updates using Messaging Queue. We will talk below about each aspect and also some of the key decisions we took while building Driver Network using microservices architecture:
Start by deciding the microservices:
While small services are preferable, it’s important to remember that small services are a means to an end, and not the primary goal. The goal of microservices is to sufficiently decompose the application in order to facilitate agile application development and deployment. But it is also important to not over-decompose the microservices, as called as nano-services. Nano-services are tougher to manage. If a service has only a few lines of code, it can be called nanoservice. If a service implements a functional piece and stores data, it can be called a microservice. If a service is just doing some non-distributed computation, it can be better a reusable component instead of a service.
As a starting point, we did break driver network functionality into various microservices. As part of the list of microservices, we also made a small service specific document on what each service will be doing. Below is a diagram depicting the microservices we planned for driver network.
Data design for microservices:
A microservice will require some or other data storage. Be it RDBMS, NoSQL DB or some big data. For the sake of isolation of services to the maximum extent possible, it is important to have two services not share the data storage. So in case, a service uses relational DB to store the data, it should have its individual database. With only that particular service allowed access. Having separate database for each service leads to data redundancy. Since two services can require same data and that data is duplicated for each service. But with the reduction of disk cost these days, it is worth the cost to keep services manageable and isolated.
In our driver network feature, we required RDBMS. For each service, we made ER diagram containing tables and relations between those tables.
Communication between services:
There are a couple of ways services can talk to each other. We narrowed down to only two:
REST API for synchronous communication – With microservices architecture, one microservice can consume functionality of other service using REST API. For REST API documentation, we did user swagger definition file. Swagger has been renamed to ‘OpenAPI’, though still referred to as Swagger in the open source world. A swagger file is used to define API endpoints, data input format, output data model, server environments, authentication schemes etc., detailed specifications can be found here. We did have to make one swagger file per microservice.
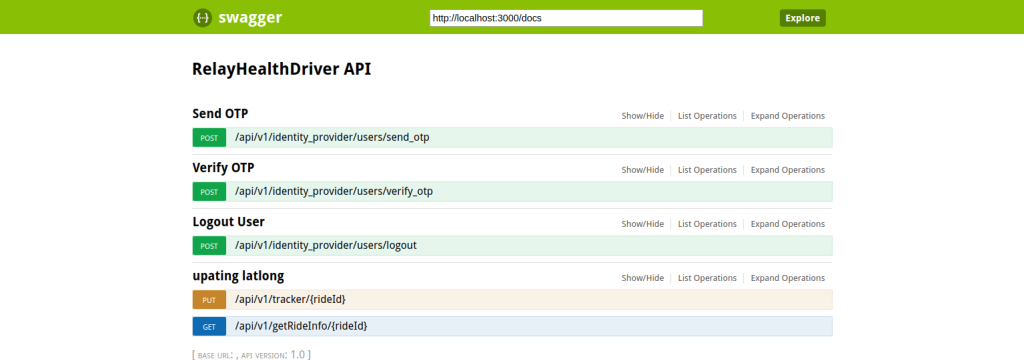
All Microservices endpoints documented in one consolidated Swagger UI Doc
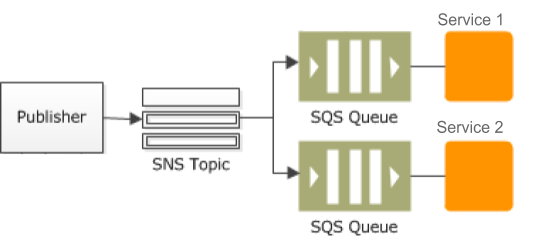
- Messaging Queue for asynchronous communication – One microservice can communicate about events to other services using asynchronous communication mechanism like messaging queue. Both these aspects(REST API & messaging mechanism) needs to be documented so that all stakeholders(microservice developers, testers, and clients) can consume it. For messaging mechanism, we did have one markdown per microservice. This markdown file contains a list of message types which the microservice can dispatch. And contains message details like:
- eventType: logical name of the event
- eventData: JSON data containing the data for the event. JSON structure is also documented in the markdown file for the microservice.
For events, we used AWS SNS as the notification mechanism. And each service who wants to listen to the events and process it will have its own AWS SQS queue. AWS SNS can fan out to multiple SQS queues (one each for service that is interested in the event). SQS also acts as a persistence mechanism for the events. So even if service isn’t available when the event arrives, an event will still be there in SQS queue to be processed later on.
Why API Gateway
An API Gateway is the single point of entry for your microservices-based application, presenting the API for each microservice and giving a clearer view of a decoupled application to the programmer.
We are using AWS API gateway which is a fully managed service and empowers us with features like, monitoring and securing applications at scale, ease of publishing, Resiliency, API Lifecycle Management, API Operations Monitoring, SDK Generation etc.
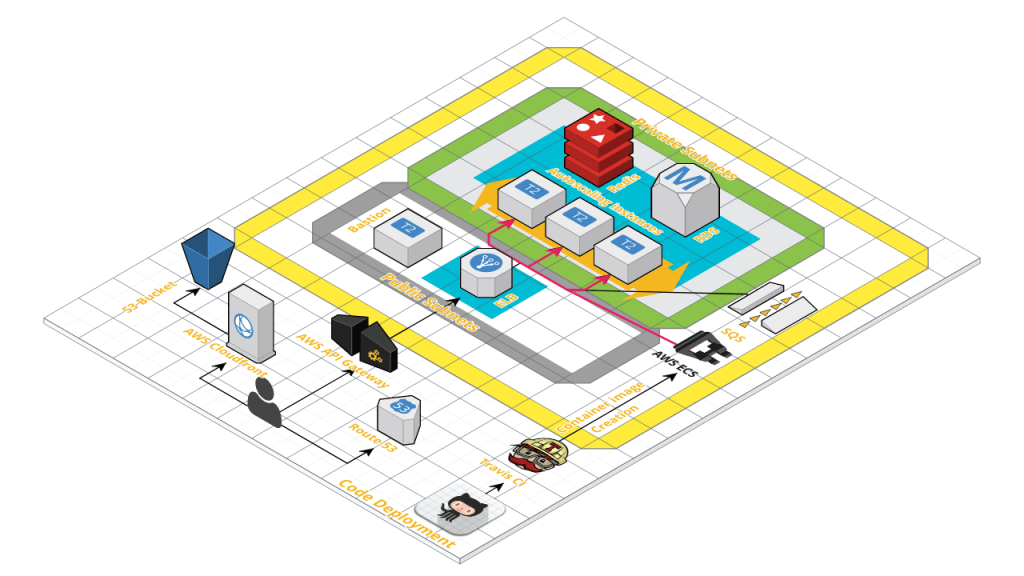
Deployment
For infrastructure of driver network, we use RDS for storage service, AWS SNS and SQS for asynchronous communication, AWS API Gateway for API proxy and AWS ECS for deploying and scaling services. Amazon offers an auto-scaling out-of-the-box for ECS. You choose the desired, minimum and a maximum number of tasks, create one or more scaling policies, and Service Auto Scaling handles the rest.
Deployment of the services is managed by Travis CI, which creates a Docker image whenever it finds an update on GitHub for a service. Once the image is created, Travis uploads it to the EC2 Container registry using IAM roles and generates a new Task definition to deploy the container updates.
Logging
With all the benefits of microservices, there also come challenges. Running a service inside a container which is writing logs to the machine volume, but after sometime you may have that container working on some other machine, reading the state of logs become a tedious job in this case and you have to ensure that you have a centralised log management solution where each container for the given service can send their logs. Centralised log management is a trivial necessity for microservices architecture, while there are many solutions in the market and one can choose depending on the application needs. We have decided to go with Graylog on top of ElasticSearch for its ease of use, beautiful UI and ability to give tiered access to anyone in the organization so developers can see operating systems logs and IT Ops people can see application logs on demand.
Testing
Each service is tested using docker-compose on a local machine first, which replicates the environment in production, it gives a clear view of the functionality of the application and the docker container itself before it is deployed to servers. Multiple containers for the same service can also be launched on the local system using docker-compose. However, proper scaling tests are done on the Dev/QA environments.
Monitoring
As discussed, we will be using the monitoring that AWS offers for containers, coupled with cloudwatch alarms and Slack alerts for each incident. If detailed monitoring is required, the likes of NewRelic can be used.
Version Management
Microservices are meant to be independent of each other. However, if there is any update that depends on another service being updated, either the developers will need to coordinate with each others to launch the dependent service along with with the service OR updated service could launch a new version of the service. In the case of later, dependent service could take its own time to become compatible with the updated service. The version management of source code for each service is managed on GitHub and container image version is managed on ECR (EC2 Container Registry).
Business Benefits
Adopting microservices architecture has quite a few business benefits:
- Agility – Microservices by design helps in agility. A change in service requires only that particular service to be tested. And with service versioning in place, other services/client dependent on this service can keep running with an older version of the service.
- Microservices architecture is high on efficiency. Since the individual service can be scaled up or down based on the demand. Hence increasing infrastructure efficiency. This leads to lesser infrastructure cost.
- It eases out the technology decisions. Since each microservice can be in different technology. This simplifies hiring decisions also quite a lot.
Summary
Microservices architecture brings many advantages to the table by decomposing an application into multiple services. It brings more agility, better change management, more maintainable code, etc. On the other side, it also comes with more complex deployment, infrastructure management, and monitoring. Having said that, it is important to weigh out pros and cons before making the decision about it.