SourceFuse adopted microservices application architecture for One Call’s Driver Network. Microservices Architecture pattern enables each microservice to be deployed independently. While the total amount of functionality is unchanged, the application is broken into manageable chunks or services, which also enables each service to scale independently. This pattern also enables better fault isolation. Fault in one service will not degrade the efficiency or working of other services. Also, each microservice can have its own technology stack (‘polyglot stack’). Furthermore, each microservice can be enhanced without impacting its dependent services/clients using version management strategies.
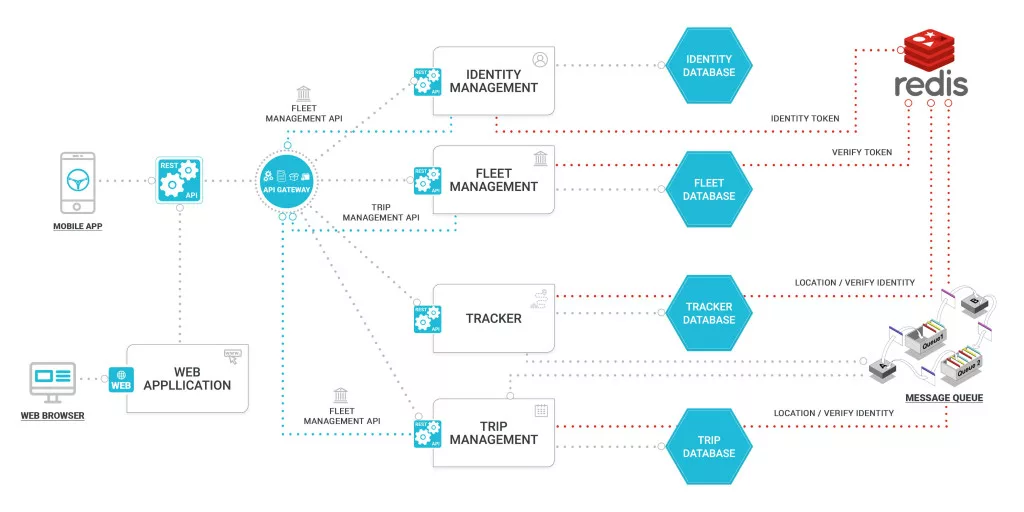
As the diagram suggests, there are multiple services together exposing application’s API using AP gateway. Each service has its own storage engine. And each service also exposes REST API to be consumed by API gateway users as well as other services. Services notify each other about data updates using Messaging Queue. We will talk below about each aspect and also some of the key decisions we took while building Driver Network using microservices architecture:
Start by deciding the microservices:
While small services are preferable, it’s important to remember that small services are a means to an end, and not the primary goal. The goal of microservices is to sufficiently decompose the application in order to facilitate agile application development and deployment. But it is also important to not over-decompose the microservices, as called as nano-services. Nano-services are tougher to manage. If a service has only a few lines of code, it can be called nanoservice. If a service implements a functional piece and stores data, it can be called a microservice. If a service is just doing some non-distributed computation, it can be better a reusable component instead of a service.
As a starting point, we did break driver network functionality into various microservices. As part of the list of microservices, we also made a small service specific document on what each service will be doing. Below is a diagram depicting the microservices we planned for driver network.
Data design for microservices:
A microservice will require some or other data storage. Be it RDBMS, NoSQL DB or some big data. For the sake of isolation of services to the maximum extent possible, it is important to have two services not share the data storage. So in case, a service uses relational DB to store the data, it should have its individual database. With only that particular service allowed access. Having separate database for each service leads to data redundancy. Since two services can require same data and that data is duplicated for each service. But with the reduction of disk cost these days, it is worth the cost to keep services manageable and isolated.
In our driver network feature, we required RDBMS. For each service, we made ER diagram containing tables and relations between those tables.
Communication between services:
There are a couple of ways services can talk to each other. We narrowed down to only two:
REST API for synchronous communication – With microservices architecture, one microservice can consume functionality of other service using REST API. For REST API documentation, we did user swagger definition file. Swagger has been renamed to ‘OpenAPI’, though still referred to as Swagger in the open source world. A swagger file is used to define API endpoints, data input format, output data model, server environments, authentication schemes etc., detailed specifications can be found here. We did have to make one swagger file per microservice.
All Microservices endpoints documented in one consolidated Swagger UI Doc
- Messaging Queue for asynchronous communication – One microservice can communicate about events to other services using asynchronous communication mechanism like messaging queue. Both these aspects(REST API & messaging mechanism) needs to be documented so that all stakeholders(microservice developers, testers, and clients) can consume it. For messaging mechanism, we did have one markdown per microservice. This markdown file contains a list of message types which the microservice can dispatch. And contains message details like:
- eventType: logical name of the event
- eventData: JSON data containing the data for the event. JSON structure is also documented in the markdown file for the microservice.
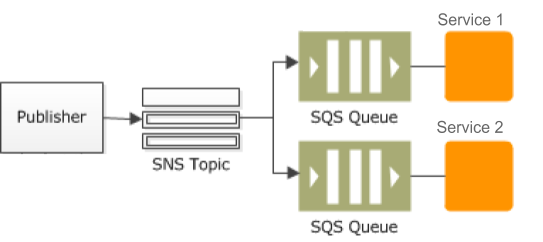
For events, we used AWS SNS as the notification mechanism. And each service who wants to listen to the events and process it will have its own AWS SQS queue. AWS SNS can fan out to multiple SQS queues (one each for service that is interested in the event). SQS also acts as a persistence mechanism for the events. So even if service isn’t available when the event arrives, an event will still be there in SQS queue to be processed later on.
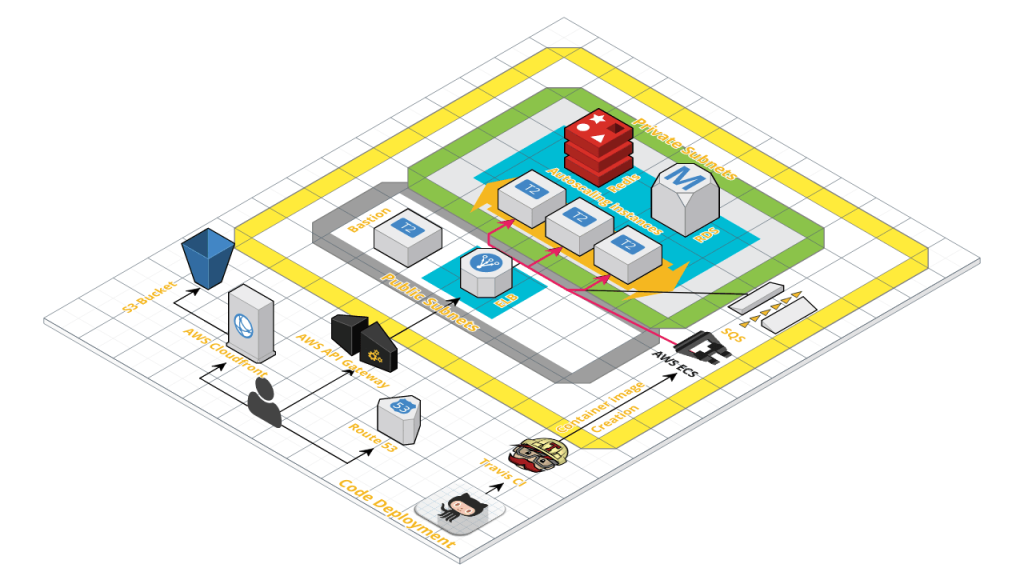
For infrastructure of driver network, we use RDS for storage service, AWS SNS and SQS for asynchronous communication, AWS API Gateway for API proxy and AWS ECS for deploying and scaling services. Amazon offers an auto-scaling out-of-the-box for ECS. You choose the desired, minimum and a maximum number of tasks, create one or more scaling policies, and Service Auto Scaling handles the rest.
Deployment of the services is managed by Travis CI, which creates a Docker image whenever it finds an update on GitHub for a service. Once the image is created, Travis uploads it to the EC2 Container registry using IAM roles and generates a new Task definition to deploy the container updates.