The world of technology is ever so dynamic, just when the world, especially the business community was wrapping its head around cloud and cloud computing…the tech world is set for another significant change. What change you wonder…it’s how ‘container orchestration’ is set to change ‘cloud computing’ as is today. But, before we establish how container orchestration is set to affect this change, let us take a quick look at the high-level history of cloud computing. Cloud computing really took off by cloud providers providing virtual machines for application deployment, I am calling this Phase 1.
Phase 1: Virtual machines for application deployment – a brief history
As per this phase, the SysOps would create multiple machines on the cloud.
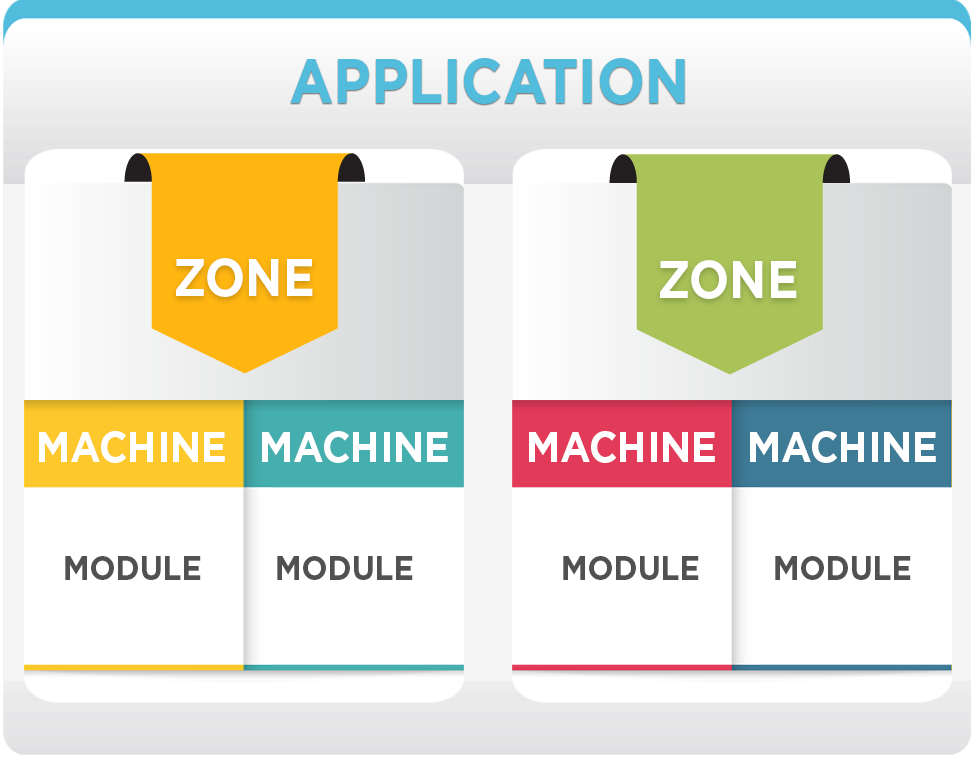
The cloud provider would set up machines in multiple zones to ensure the availability, in case a certain zone goes down, the application is still running.
Each machine had one primary module install, e.g. MySQL, Redis, Apache Server, etc. A machine could have multiple modules, but only one primary module – and for scalability/availability reasons the same module across machines were deployed, e.g. replica set in MongoDB, master-slave in MySQL, etc. And to sum it, machines will be used for one application specifically.
Phase 2: Cgroups and Cloud providing a bit more than virtual machines
One of the remarkable things in any technology evolution is that many developments tend to shape simultaneously and in parallel. While the cloud providers started providing basic and isolated services simultaneously, almost in parallel ‘Cgroups (abb. ‘control groups’)’ was released.
Setting up NAS, network security, etc wasn’t easy. Because of this, cloud service providers started providing these critical services at the click of a button or infrastructure as code, for example, ‘persistent file storage’, ‘persistent object storage’, ‘private cloud’, ‘load balancer’, etc.
In parallel Linux came up with the feature of ‘Cgroups’., ‘Cgroups’ is a Linux kernel feature that limits, accounts for, and isolates the resource usage (CPU, memory, disk I/O, network, etc.) of a collection of processes. This development has enabled the revolution in computing. This enables a further level of virtualization by having multiple isolated groups in any virtual/physical machine. And this virtualization is much lighter on CPU, memory, and disk as compared to a typical virtual machine.
Phase 3: Development = Parallel, Synchronous, Simultaneous…
Continuous Integration and Deployment have tools matured and gained popularity, and tools such as ‘Terraform’ helped in ‘Infrastructure as code’. The code which can set up an infrastructure of an application in the cloud, once this code is changed, it syncs up infrastructure based on the changes, automating the setup of infrastructure. Also, there was an abundance of scripting tools such as ‘Chef’ which automates the setup of each machine inside the infrastructure. There were also a bunch of automation tools like Jenkins which helped in automated deployment on click of a button or code change in source code version system (e.g. GitHub). These bunch of automation as well ‘infrastructure as code’ technologies moved the focus from SysOps to DevOps.
‘Docker’ provides an additional layer of abstraction and automation of operating-system-level virtualization using isolation features of the Linux kernel such as Cgroups and kernel namespaces, and a union-capable file system such as OverlayFS and others to allow independent “containers” to run within a single Linux instance, avoiding the overhead of starting and maintaining virtual machines.
Cloud providers seeing the pain of users had to go through launching and setting up instances started providing various services like a relational database, NoSQL database, data analytics, message queue, machine learning, etc. These services require just a few clicks to use, or a few lines of infrastructure as code. Hence, taking away the pain of setting up, configuring security, monitoring, et.al. While these services cannot be categorized in PaaS or IaaS, ‘Machine learning service’ could be called MLaaS. On similar grounds, database services can be classified as DBaaS.
Now, depending on the cloud provider, these services could be auto-scalable following a ‘pay as you use’, or they could be provisioned by the cloud provider based on the scale requested. As it is, a certain service could be built on top of existing technology, for instance, PostGres database as a service.
In case of certain features not available from a service, a cloud provider may build and release the enhancement (depending on time and the magnitude of demands). And, it could be that a service is using proprietary technologies of a cloud provider, if so is the case, using such a service locks our data and our app with the service. There is a feature lock-in as well, but we get the advantage of an easy setup of the service; gaining short-term but losing the flexibility in long-term. This can be termed as ‘Service lock-in’.
Phase 4: Current Phase – Maturing Container Orchestrations
‘Container orchestration’ is the process where multiple containers (e.g. Docker) can together form an application module (e.g. web server) and multiple modules can together form an application (e.g. Any SaaS web application). And this application isn’t deployed exclusively on a bunch of machines, rather it is deployed on a cluster (i.e. infrastructure) which could be formed by technologies like Kubernetes, Docker Swarm, AWS ECS, etc. And multiple applications can be deployed on the same cluster – so, in a way logical separation between application and cluster. The current phase shows that container orchestration engines are maturing; below is a representation of this logical separation.
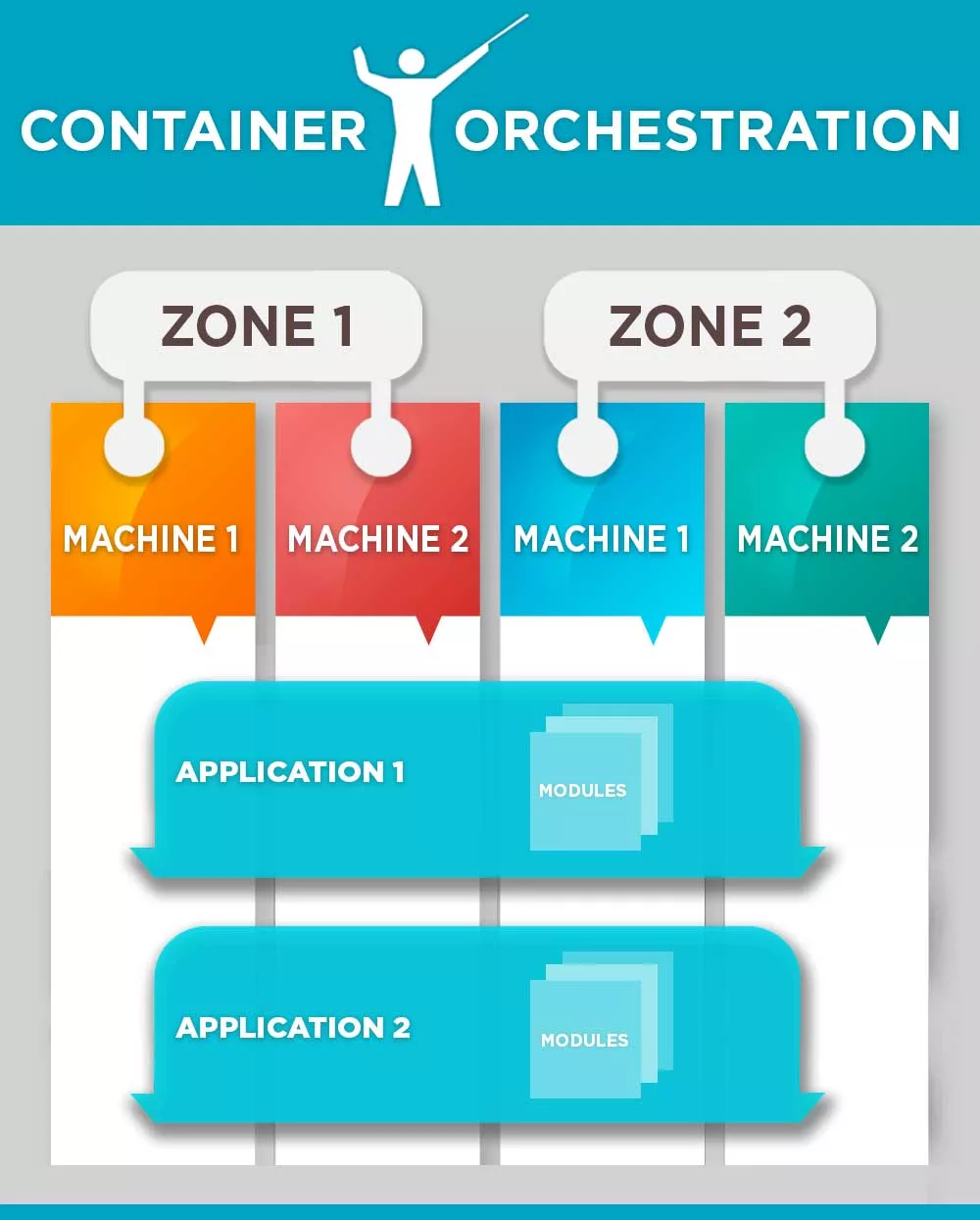
The benefits being:
- Optimal utilization of infrastructure: Since the same infrastructure could be used for multiple applications.
- Enables the use of microservices architecture.
- Application scalability can happen automatically based on the configuration by orchestration engine itself. And if cluster falls short of the capacity or has excess capacity, the cluster could auto-scale as well. Hence saving on cost while automatically scaling the application.
- Application deployment on a cluster would get standardized since they will use same deployment strategy, log management, and infra monitoring strategy.
- Different applications can get isolated using the orchestration engine specific concepts, e.g. namespace in Kubernetes. There can be applications, users, resource constraints, secrets, etc., isolated in a namespace.
- Cluster deployment team can be separate from application deployment team. We at SourceFuse have built a cluster deployment team which has set up and maintains the cluster. And we have a development environment of various projects being set up by application deployment team.
Everything comes with its own nuances, with container orchestration, isolation between applications isn’t as strong as hypervisor-based machine virtualization. Two containers or applications can share a disk volume if configured to do so, hence not complete isolation. At the current level, it is better to have multiple applications deployed on the same cluster if and only if the cluster is set up and used for the same organization.
Phase 5: Future is Here!
The future is technically already here and based on the aforementioned advancements, I perceive, container orchestration will mature over next couple of years. In parallel, world-class technologies will be wrapped in a packaging system. Packaging system will be aware of cluster and availability zone; and will install the technology as well as automatically configure it for availability, scale, security, permissions, logging, monitoring, etc. For instance, there could be PostGres package for Kubernetes which installs PostGres on the Kubernetes cluster for production configuration, and not just for development use.
Similarly, we can have Apache Spark, Apache Storm, RabbitMQ, Redis, NodeJS, PrestoDB, etc. packaged for the container cluster. This would ease the deployment of these technologies, and get rid of service lock-in as mentioned in Phase 3. Which means that cloud providers will be concentrating on IaaS and basic necessities around it, e.g. private cloud, file storage, etc. and MLaaS, DBaaS, etc. won’t be preferred way for people to use since people will have flexibility on choice of technology by deploying technologies directly in a cluster. Which means that cloud provider who provides best IaaS will win and cloud providers will be providing open source container orchestration engines as services!
In light with the recent developments – looks like the future is indeed here and my intended predictions are late ( ref: EKS services as launched by AWS) So, as the next in series, we will be coming back with our key findings or better still, the next to next-gen predictions!

